
在研究某些課題的時候,不免會遇到許多 PDF 文件。
PDF 文件本身沒有問題,有問題的是他們若是由「圖片組成」的文件,而我們只是要閱讀與列印的話,其實也沒有問題,但若要對 PDF裡面的文字 進行再處理,就會很麻煩。
如果可以將這些 PDF 文件中圖片裡的文字,自動辨識且轉換成文字,對我來說,那將是一件很美好的事情。
目前 OLOCR(https://olocr.com/zh-TW)這個網路服務,可以達成我的需求。
對於這類網路服務,基本上我的需求很簡單:「可多頁處理」、「不上傳資料」。
OLOCR(https://olocr.com/zh-TW) 除了可以滿足前兩者之外,他還「免註冊」!
基本上,連上之後,就會使用了,而文字辨識重點有二:「準確性」與「抗雜訊性能力」。
所以,我將我的讀書註記(共有3頁,且頁面有不同顏色劃記的雜訊)拿來實驗,結果如下:
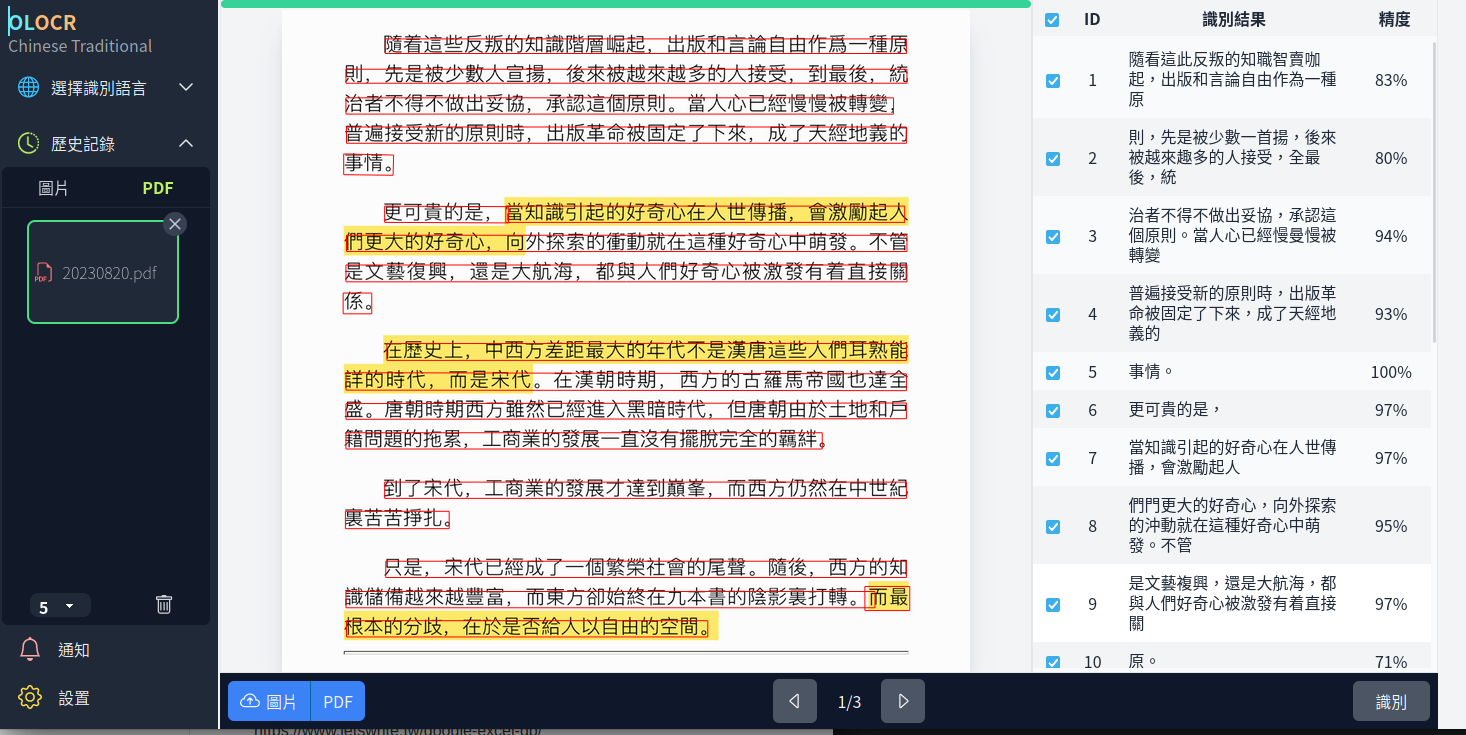
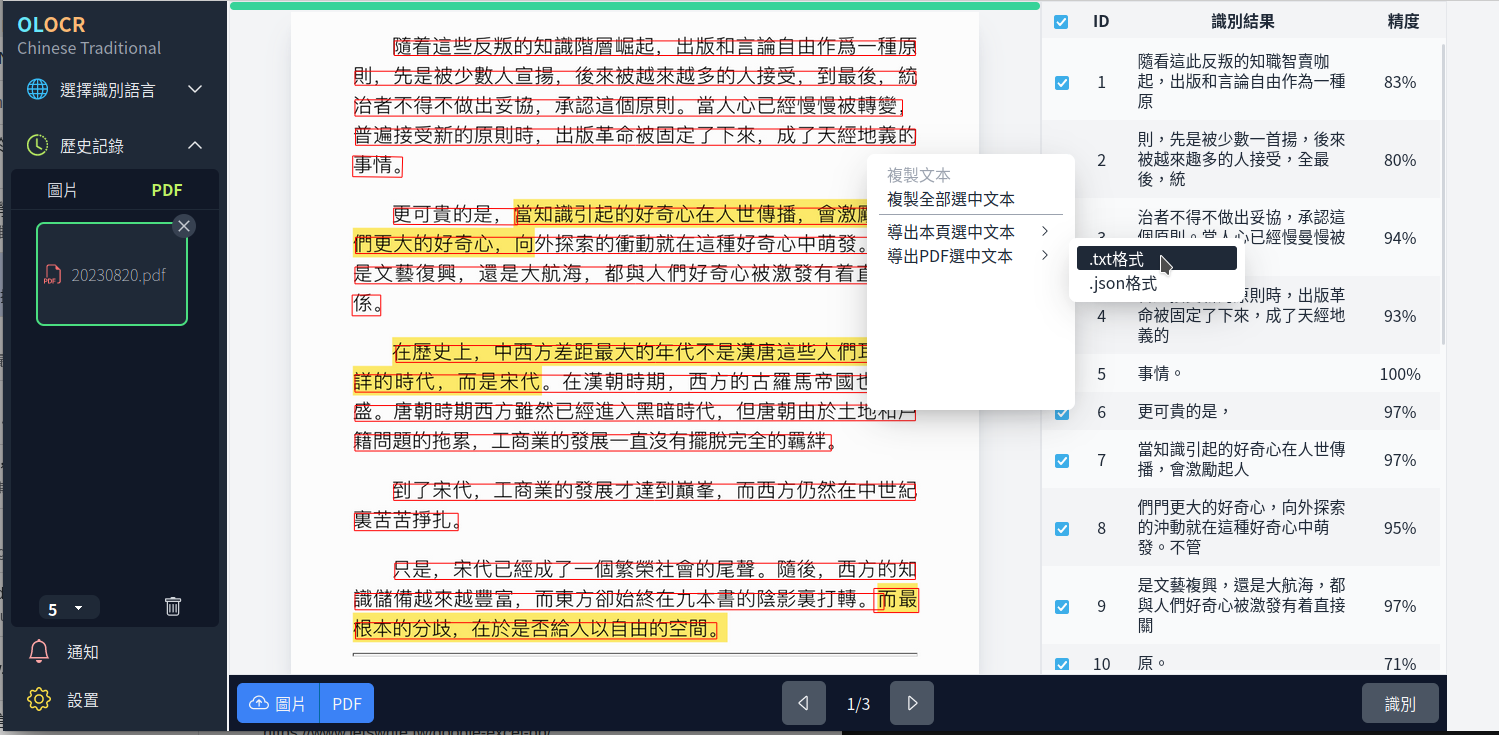
效果令我相當滿意,而且只要在文件上「按右鍵」,還可以將辨識結果,存成文字檔,這樣就能對於文件內容進行再處理了。
除了「PDF」文件之外,其實圖片也可以辨識,不過一次只能一張,不能批次處理,所以如果是我,我便會將所有的圖片按照順序,轉成 PDF 文件,然後再來進行文字辨識處理。
參考資源
- OLOCR 網站
- OLOCR 免費文字辨識 OCR 工具,批次轉換圖片 / PDF 無限制